Изучение data science c нуля: этапы и вехи
Содержание:
- Семплирование
- Решаем задачи целиком
- Что Data Scientist и Data Engineer могут делать в одной компании?
- Ожидания не соответствуют реальности
- Немного истории: как появилась Data Science и при чем тут большие данные
- Как им стать
- Необходимые инструменты для работы
- Вакансии и зарплата, перспективы профессии
- Профессия Data Scientist
- Дисперсия
- Искусственный интеллект
- 2017: Высшая школа экономики будет обучать Data Culture на всех программах бакалавриата
Семплирование
Предположим, вам требуется решить важную задачу: выяснить среднюю ширину морды домашних котов нашей страны. Прямой способ, то есть измерение всех домашних питомцев, невозможен по ряду объективных причин. Придётся ограничиться выборкой — взять какое-то число животных, измерить морды именно им и сделать выводы по итогам только этих исследований.

Иллюстрация: Pixabay
Но тут сразу же возникают вопросы:
- Сколько и каких котов отобрать для замера?
- Почему именно этих, а не других?
- Какие есть гарантии, что вычисленное значение действительно будет средней шириной морды всех котов России?
Семплирование — это группа статистических методов и приёмов, отвечающих на эти вопросы. С помощью семплирования мы формируем нашу выборку так, чтобы она наилучшим образом отражала свойства генеральной совокупности — то есть свойства всех котов страны.

Качественная выборка сохраняет свойства всей генеральной совокупности
Иными словами, вы не можете измерить N первых попавшихся котов и обобщить результат для остальных. Выборка должна хорошо «сидеть» во всей популяции кошек, чтобы можно было делать обоснованные выводы. Такую выборку называют релевантной.
Кстати, статистика и котики — близнецы-братья. После выхода одноимённой книги Владимира Савельева мы говорим «статистика», а подразумеваем «котики», и наоборот. И смело рекомендуем эту книгу всем, кто дочитал до этого места.
В Data Science методы семплирования применяются при разработке, подготовке и оценке датасетов, чтобы они одновременно и были упорядоченными, и соответствовали реальности.
Решаем задачи целиком
Пол Хиемстра, преподаватель и практик Data Science, даёт три совета тем, кто хочет эффективно изучать науку о данных.
Работайте над проектами целиком. У начинающих дата-сайентистов обычно скромная роль, они отвечают за небольшие кусочки проекта. Эту проблему решает pet-проект, который можно делать параллельно с основной работой. Он поможет помнить о масштабе и не работать над разными этапами по отдельности. Конечно, придётся осваивать и точечные навыки (например, какую-нибудь Python-библиотеку), но потом сразу возвращайтесь к целой задаче.
Как сделать pet-проект: найдите датасет из интересующей вас области и проанализируйте его, например, по методологии CRISP-DM. Описывайте каждое своё действие, а главное — соединяйте шаги между собой. Для этого подойдут сервисы типа Google Colab и Jupyter Notebooks. Подробный отчёт о pet-проекте украсит ваше портфолио.
Найдите хорошего наставника. Обсуждать свою работу с опытным дата-сайентистом — хорошая практика. Так вы прокачаете метакогнитивные навыки, которые необходимы для быстрого разбора сложных проблем. В общении с наставником старайтесь фокусироваться на том, как вы решаете проблему — то есть на подходе и идеях, а не на самом решении (коде, модели, библиотеке). Вопросы «а как…» позволяют максимально раскрыть и перенять опыт.

Найдите единомышленников. Объяснение своих решений другим людям, ответы на их вопросы — прекрасный способ лучше понять собственную работу. Помните незадачливого «препода» из анекдота, который на третий раз уже и сам понял, что говорит, а студенты так и не смогли? Так вот — это не просто шутка. А слушая решения других, пытайтесь в первую очередь выяснить, почему ваш собеседник сделал что-либо (например, выбрал конкретную модель).
Что Data Scientist и Data Engineer могут делать в одной компании?
У исследователя данных и дата-инженера обычно разные цели. Первый непосредственно решает запросы бизнеса: для этого он проверяет гипотезы и строит прогнозные модели. Второй отвечает за оптимальное и надежное хранение данных, их преобразование, а также за быстрый и удобный доступ к ним. Это позволяет дата-сайентисту работать с корректными и актуальными данными. Компании, которые хотят использовать Data Science для развития своего бизнеса, могут нанимать и дата-инженера, и дата-сайентиста.
Пример: в онлайн-магазине бытовой техники каждый раз, когда посетитель сайта нажимает на тот или иной товар, создается новый элемент данных.
Дата-инженер может собрать эти данные и сохранить в удобном для доступа формате. Дата-сайентист получает данные о том, какие клиенты купили те или иные товары, и использует эту информацию так, чтобы предсказать вариант идеального предложения для каждого нового посетителя сайта.
Пример: работа в платной онлайн-библиотеке. Если компания хочет узнать, какие пользователи тратят больше денег, им нужны компетенции и дата-сайентиста, и дата-инженера. Инженер соберет информацию из логов сервера и журналов событий сайта и создаст пайплайн, который соотносит данные с конкретным пользователем. Затем инженеру нужно будет обеспечить хранение полученной информации в базе данных так, чтобы ее можно было без труда запросить. После этого дата-сайентист сможет проанализировать действия пользователей сайта и узнать особенности поведения тех, кто тратит больше денег.
Ожидания не соответствуют реальности
Эта цитата так правдива. Многие младшие дата-сайентисты (включая меня) решили заняться наукой о данных, потому что хотели решать сложные проблемы при помощи крутых новых алгоритмов машинного обучения, которые оказывали бы огромное влияние на бизнес. Мы верили, что будем заниматься чем-то действительно важным. Однако все оказалось совсем не так.

Фото: Medium
Я уверен: одна из главных причин, почему дата-сайентисты бросают работу, заключается в том, что их ожидания не соответствуют реальности.
Все компании очень разные, тем не менее, многие предприятия, не имея подходящей инфраструктуры, нанимают дата-сайентистов, чтобы начать получать выгоду от искусственного интеллекта. Это становится причиной «холодного старта» в ИИ. А теперь добавьте ко всему тот факт, что компании предпочитают нанимать опытных сотрудников, но у них это не получается. От этого страдают обе стороны. Дата-сайентисты устраиваются в разные организации, чтобы писать умные алгоритмы машинного обучения, но не могут этим заниматься, потому что сначала им нужно разобраться с инфраструктурой данных.
Цели компании должны совпадать с целями сотрудников.
Кроме того, многие дата-сайентисты верили, что смогут оказать влияние на людей во всем мире. В реальности же, если машинное обучение – не основная деятельность компании, скорее всего, вы будете нужны лишь для того, чтобы обеспечивать небольшой прирост прибыли. Конечно, вы можете заниматься чем-то очень важным, но это происходит довольно редко.
Немного истории: как появилась Data Science и при чем тут большие данные
В отличие от термина «большие данные», который стал популярен с 2010-х гг., наука о данных зародилась намного раньше, во второй половине 20-го века. Первое упоминание этого понятия датируется 1974 годом, когда вышла книга Петера Наура. В этой публикации Data Science определяется как дисциплина по изучению жизненного цикла цифровых данных, от момента их появления до преобразования и использования в других областях знаний. Тем не менее, широкое употребление этот термин получил лишь в 1990-е годы, а общепризнанным стал только в начале 2000-х. В частности, в 2002 году междисциплинарный Комитет по данным для науки и техники начал выпускать журнала CODATA Data Science Journal, а в январе 2003 года вышел первый номер The Journal of Data Science Колумбийского университета .
Следующая волна интереса к DS возникла при популяризации понятия Big Data, с 2010 года, когда вычислительные мощности даже бытовых компьютеров стали позволять работать с большими объемами данных. Примерно с этого же времени стали проводиться многочисленные профессиональные конференции, а университеты по всему миру включили эту дисциплину в свои учебные курсы, разработав соответствующие образовательные программы.
Сегодня Data Science активно применяется в широком спектре прикладных областей деятельности: от астрономии до медицины, включая коммерческие кейсы: маркетинг, ритейл, менеджмент, финансовый анализ, предиктивная аналитика чрезвычайных ситуаций и т.д.
Как им стать
Учеба обязательна для этой профессии. Причем учиться надо много, долго и основательно. Для начала надо освоить азы математики, статистики и информатики, а дальше изучить языки программирования, лучше начать с Python.
На блоге iklife.ru собраны лучшие курсы по Python для начинающих и опытных программистов, которые будут полезны при освоении должности Data Scientist.
Также рекомендую вам прочитать следующие книги:
- Брендан Тирни, Джон Келлехер “Наука о данных”
- Кирилл Еременко “Работа с данными в любой сфере”
- Уэс Маккинни “Python и анализ данных”
Куда пойти учиться
Лучшее обучение – это онлайн-обучение. Платформы Skillbox, Нетология, GeekBrains, SkillFactory, ProductStar и Stepik предлагают свои обучающие программы:
- Профессия Data Scientist
- Data Scientist
- Data Science с нуля
Ознакомиться с полным перечнем курсов для Data Scientist можно на нашем блоге.
Уточню, что на этом учеба не должна заканчиваться. Data Scientist – это такая профессия, которая предполагает непрерывное обучение. Даже если вы уже работаете, периодически повышать свой уровень надо обязательно. К тому же выбор достаточно широк – это и онлайн-курсы, и тренинги, и конференции.
Где найти работу
Сложно сказать, где именно искать работу по этой профессии. Не из-за того, что мало мест, а, наоборот, потому что нет такой сферы бизнеса, где нельзя было бы применить талант этого специалиста. Ему доступна как работа в офисе, так и удаленно на дому.
Он востребован в таких областях деятельности как:
- IT-сфера,
- медицина,
- банковские структуры,
- СМИ,
- торговля,
- политика,
- транспортные компании,
- страховые фирмы,
- сельское хозяйство,
- наука,
- метеослужбы.
Как я уже говорила, Data Scientist нужен во многих сферах, где необходимы прогнозы, анализ рисков и поведения клиентов. Поэтому список можно дополнить.
Перед откликом на вакансию надо подготовить резюме. В нем сосредоточиться в первую очередь нужно на математических и IT-навыках, опыте работе, успешных проектах и достижениях. Описание должно получиться кратким, лаконичным и простым. Специалисту надо прикрепить портфолио к резюме.
Учтите, что вакансии на эту должность не всегда называются именно “Data Scientist”. Работодатели могут написать, что требуется IT-аналитик, специалист по анализу систем, аналитик Big Data.
Необходимые инструменты для работы
Когда выбрана одна конкретная стезя в аналитике, стоит разобрать в том, какие инструменты могут пригодиться для дальнейшей работы. Мало обладать теоретическими знаниями. Без комп. программ и утилит обрабатывать сведения в электронном виде невозможно. Особенно тогда, когда речь идет о больших ее объемах.
Многое зависит от того, какой именно специалист приступает к работе. Ориентироваться можно на следующие советы:
- Все «ученые по обработке и аналитике материалов» должны разбираться в таблицах, СУБД, хранилищах, SQL и ETL.
- BI-аналитик: инструментарий BI (Power BI, Tableau, OLAP, майнинг), SAS, R, Python, Knime, RapidMiner.
- Специалистам по данным и «ученым»: библиотеки визуализации и проведения досконального анализа в R и Python, углубленное изучение майнинга, Docker, Airflow.
- Инженерам: углубленные познания в ETL-процессах, а также в процессах выстраивания пайплайна.
Также предстоит задуматься над тем, чтобы углубиться в программирование. Обязательно знать SQL, а также Python. В идеале дополнить соответствующий багаж Scala и Java.
В аналитике часто задействуются облачные платформы. Если потенциальный «ученый» хорошо в них разбирается, добиться успехов в карьере ему будет не слишком трудно. А еще рекомендуется изучить технологии обработки сведений в огромных объемах (Kafka, Hadoop, Spark).
Навыки и умения
Комп – не единственное, что должен освоить будущий «ученый по информации». Такой специалист обладает определенными навыками и умениями.
Для более быстрого продвижения по карьерной лестнице, а также для того, чтобы стажировка не доставляла хлопот, человеку пригодятся следующие качества и навыки:
- абстрактность мышления;
- наблюдательность;
- наличие логики (чем больше она развита – тем лучше);
- высокий эмоциональный интеллект;
- умение работать в команде и конструктивно воспринимать критику;
- усидчивость;
- навыки программирования;
- способность быстро получать, преобразовывать, очищать и структурировать поступаемые сведения;
- умения создавать презентации, рисовать диаграммы;
- проведение исследований и A/B-тестов;
- спектр познаний в математических методах и основах статистики;
- способность создавать скетчи и разнообразные прототипы.
Также для работы потребуется мощный компьютер, но им обычно снабжает работодатель. В некоторых ситуациях Data Science предусматривает подключение суперкомпьютеров.
Вакансии и зарплата, перспективы профессии
Эта профессия достаточно молодая, но уже востребована на рынке. Количество данных растет в геометрической прогрессии и требует нестандартного подхода к обработке. Традиционное машинное обучение не срабатывает, нужен совершенно другой подход.
Специалистов разного уровня недостаточно, спрос на их услуги очень высок
Но важно понимать, что выйти на достойную оплату труда за несколько месяцев для Data scientist невозможно. Но для старта в профессии достаточно иметь отличную математическую базу, навыки программирование и знать алгоритмы
В зависимости от уровня знаний и опыта работы зарплата специалиста будет следующая:
|
Квалификация (уровень знаний) |
Опыт работы и зарплата |
|
Junior |
Опыт работы до 1 года. Специалисты этого уровня уже знают базовые модели и могут их адаптировать для решения конкретной задачи. Умеют визуализировать данные. Зарплата специалиста 60 000 – 120 000 рублей. |
|
Middle |
Опыт работы 1-3 года. Специалисты этого уровня уже могут обучать прототипы и подбирать модель под конкретную задачу. Они хорошо понимают потребности бизнеса и могут быстро решить задачу. Зарплата специалиста 150 000 – 180 000 рублей. |
|
Senior |
Опыт работы от 3-х лет. Специалист такого уровня уже может управлять командой, быть связующим звеном между исполнителями и бизнесом. Он хорошо разбирается в распределенных вычислениях, может быстро обучить прототип на незнакомых данных для оценки эффективности новой идеи. Зарплата специалиста 180 000 – 270 000 руб. |
Самые свежие вакансии с кратким описанием требований к кандидату
Итак, начинающий специалист может рассчитывать на зарплату от 60 000 рублей. Востребованность и высокую оплату подтверждают следующие вырезки только с одного сайта с вакансиями:





Направления развития в профессии
Data scientist всегда работает в команде, состоящей из аналитиков и инженеров данных. Каждый специалист занимается только одним направлением:
- Data engineer – инженер данных, отвечает за создание и поддержку инфраструктуры, обеспечивая сбор, хранение и управление потоками данных в реальном времени.
- Chief data officer – директор по данным, управляет жизненным циклом данных так, чтобы каждый специалист получал нужную информацию в подходящем виде и приемлемом качестве. Контролирует работу других специалистов.
- Data mining – аналитик данных, который обрабатывает исходные данные и предоставляет их в компактном виде.
- Text mining – аналитик текстов, который обрабатывает и разделяет тексты на категории, извлекая информацию и обрабатывая изменения.
Сферы применения Data scientist
В настоящее время формирование и обработка баз данных есть в любой сфере деятельности. В реальной жизни специалист может найти применение своих знаний в следующих отраслях:
|
Отрасль |
Пояснения |
|
Производство |
Необходимо мониторить текущие процессы и находить причины возникновения брака. Предлагать варианты оптимизации и улучшения качества продукции. Планировать различные эксперименты и предлагать новые виды продукции. |
|
Энергетика |
Основные задачи специалиста состоят в прогнозировании объемов потребления и цен на электроэнергию. Он может провести диагностику объектов и рассчитать оптимальные тарифы. Предложит оптимизировать режим потребления электроэнергии, подготовит заявки на почасовое потребление. |
|
Ритейл |
Необходимо прогнозировать спрос и цены, отток или увеличение количества клиентов. Анализировать предпочтения потребителей. Оптимизировать склады и логистику для увеличения эффективности. |
|
Финансы |
Оценивать риски и резервные фонды. Отслеживать мошенничество и возможные риски неисполненных кредитных обязательств. Построение инвестиционных моделей входит в задачи специалиста. |
Профессия Data Scientist
Интернет и базы данных – это большие объемы неструктурированной информации, «вываленной» в сеть. И каждая компания хочет выделить и оценить конкретные данные; например, институт эпидемиологии желает получить отчет о развитии конкретного вируса, маркетинговое агентство – вычислить современные тренды, а Министерство образования сопоставить успеваемость в прошлом и текущем десятилетии.
Получается, перед Data Scientist ставится задача собрать и проанализировать информацию, а в некоторых случаях дать прогноз. Естественно, без компьютерных технологий структурировать массивы данных не получится. Но не думайте, что Data Scientist просто ищет информацию и складывает ее в правильной последовательности.

Современная наука о данных работает с алгоритмами, заменяющими людей, чат-ботами, искусственным интеллектом и так далее. Дата-сайентист должен обладать навыками программирования, так как он сам пишет нужные алгоритмы.
Data Scientist востребован везде, где есть данные, подверженные структуризации и алгоритмизации:
- Бизнес. Например, специалист может написать алгоритм, упрощающий сбор статистических данных.
- Банковские системы. Выдача онлайн-кредитов, оформление заявок на вклады и прочие банковские услуги регулируются алгоритмами, написанными дата-сайентистом.
- Транспорт. Построение оптимального маршрута, написание алгоритма выявления пробок.
- IT. Боты, поисковые системы, искусственный интеллект.
- Промышленность. Прогнозирование сбоев в работе или нехватки сырья.
- Медицина. Современные медицинские приборы предполагают автоматические диагнозы на основе симптомов. Алгоритмы анализа помогают врачам индивидуально работать с пациентами и назначать наиболее эффективное лечение.
- Другие области науки. Генетика и биоинженерия не обходятся без Data Science.
Областей применения Data Science очень много, поэтому профессия крайне востребована. Если до сих пор не совсем понятно, чем занимается Data Scientist, то вот базовая последовательность его действий при получении конкретной задачи:
- Получение технического задания от заказчика.
- Специалист оценивает задачу и пробует выполнить заказ методом машинного обучения.
- Дата-сайентист ищет дополнительные данные и критерии оценки, так как главное – эффективность модели.
- После этого он приступает к программированию и тренировке алгоритма.
- Когда модель будет готова, он испытывает ее на предмет выполнения задачи; подключаются другие специалисты, например риск-менеджеры.
- Если все работает как нужно, алгоритм внедряется в производство.
- После введения модели в эксплуатацию Data Scientist следит за процессами, по необходимости дорабатывая или улучшая алгоритм.
На данный момент это одна из самых высокооплачиваемых и перспективных вакансий в мире. В России Data Scientist уровня senior зарабатывает до 300 000 тыс. в месяц.
Дисперсия
Дисперсия — это величина, показывающая, как именно и насколько сильно разбросаны значения — например, предсказания модели машинного обучения или доход за рассматриваемый период. За точку, относительно которой эти значения разбросаны, берут истинное значение, целевую переменную или математическое ожидание, которое вычисляется теоретически и заранее.
Часто в качестве матожидания выступает обычное среднее арифметическое. Например, математическое ожидание количества очков при броске игрального кубика равно среднему арифметическому очков на всех гранях:
(1 + 2 + 3 + 4 + 5 + 6) / 6 = 21/6 = 3,5
Представьте себе тир, стрелка и мишень. Снайпер стреляет в стандартный круг, где попадание в центр даёт 10 баллов, в зависимости от удаления от центра количество баллов снижается, а крайние области дают всего 1 балл. Каждый выстрел стрелка — это случайное целое значение от 1 до 10.
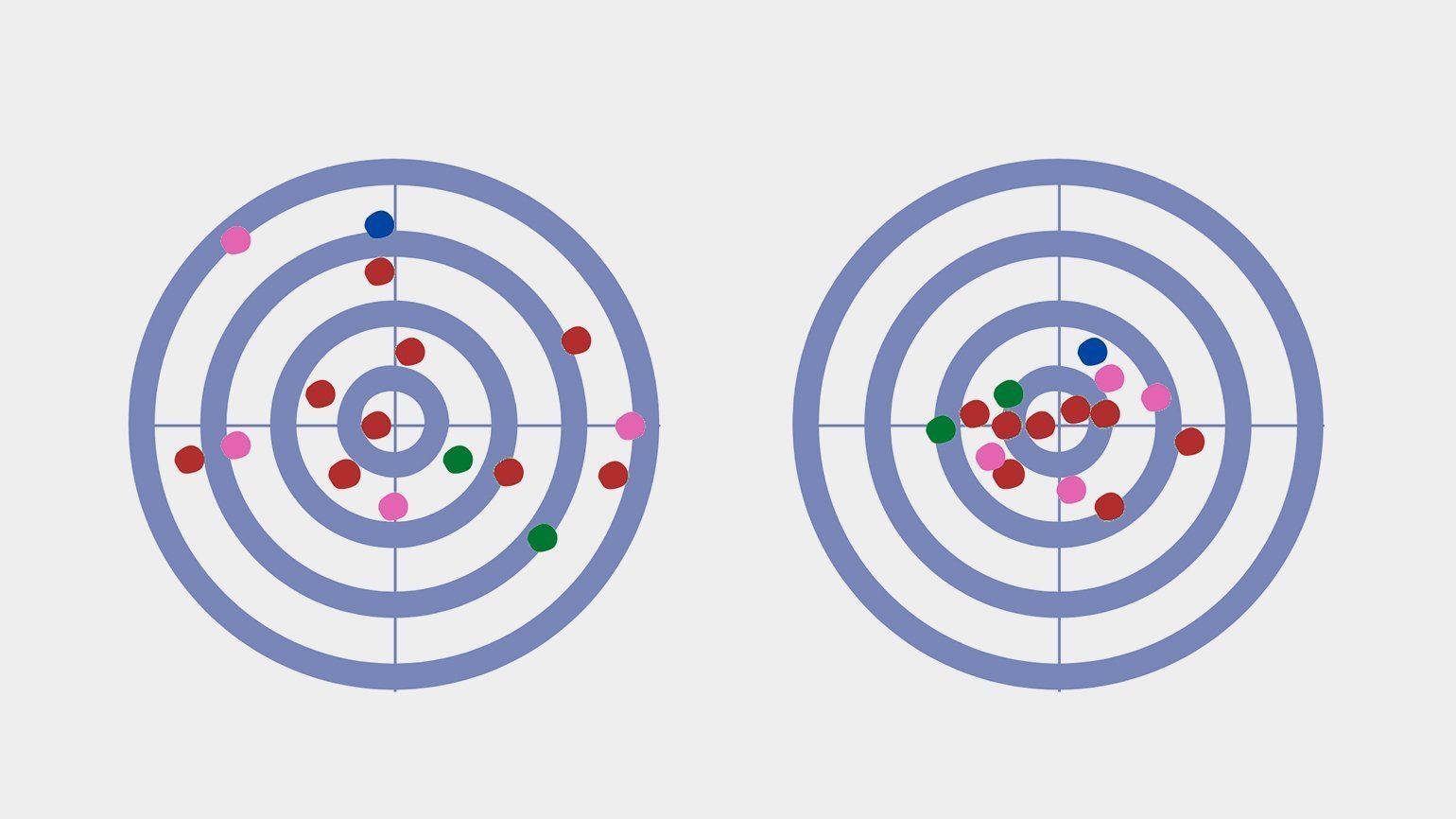
Высокая и низкая дисперсия
Изрешечённая пулями мишень — отличная иллюстрация распределения. Дисперсия здесь — величина, обратная кучности попаданий: хорошая кучность означает низкую дисперсию, и наоборот.
Искусственный интеллект
Искусственный интеллект — научное направление, в рамках которого ставятся и решаются задачи аппаратного или программного моделирования тех видов человеческой деятельности, которые традиционно считаются интеллектуальными.
Исследования, связанные с ИИ, высокотехнологичны и узкоспециализированны. Одной из ключевых задач искусственного интеллекта является программирование компьютеров, которые демонстрируют такие способности, как понимание, рассуждение, решение проблем, восприятие, обучение, планирование и т. д.
Основные составляющие ИИ — машинное обучение, инженерия знаний (knowledge engineering) и робототехника.
Принимая во внимание перечисленные научные области, концепции, и инструменты, мы можем без труда заключить: Data Science — это наше будущее, причем ближайшее. Курс
Курс
Data Science с нуля
Освойте все необходимые инструменты для уровня junior и получите самую востребованную IT-профессию 2021 года.
- 8 проектов в портфолио;
- соревнования и хакатоны;
- помощь в трудоустройстве.
Узнать больше
BLOG +5% скидки
Перевод: Тимонина Мария
2017: Высшая школа экономики будет обучать Data Culture на всех программах бакалавриата
НИУ ВШЭ первым из российских университетов начнет формировать компетенции по Data Science у всех студентов, обучающихся на программах бакалавриата. В рамках проекта Data Culture расширится набор дисциплин и появятся образовательные треки по анализу больших данных.
Data Culture – это общий термин для обозначения навыков и культуры работы с данными. Высшая школа экономики считает, что запуск проекта, направленного на воспитание у студентов таких навыков, сейчас актуален из-за огромного потенциала использования больших данных и трансформации профессий, которые, так или иначе, используют или могут использовать большие массивы информации. Потребность рынка в специалистах с компетенциями по анализу данных, перерастает в необходимость воспитания во всех предметных областях профессионалов, понимающих возможности и ограничения массивов данных, потенциал и особенности методов машинного обучения, а в ряде направлений и умеющих пользоваться этими технологиями и инструментами.
Проект Data Culture станет продолжением интеграции в образовательные программы НИУ ВШЭ элементов, направленных на воспитание у студентов культуры и умений работы с данными. Он расширит возможности студентов уже абсолютно всех образовательных программ по формированию компетенций, связанных с Data Science. Это позволит выпускникам в перспективе быстро и эффективно интегрироваться в решение профессиональных задач на стыке предметных областей и компьютерных технологий, которые сегодня являются передовыми, но уже в ближайшей перспективе станут привычной практикой.
Проект включает разработку отдельных курсов по Data Science так или иначе кастомизированных под специфику образовательных программ, а также формирование специализированных образовательных треков из таких курсов с разной степенью сложности: начального, базового, продвинутого, профессионального и экспертного уровней. Это связано с большим разнообразием образовательных программ, студенты которых дифференцированы по базовым компетенциям в сфере математики и информатики. Для программ или их блоков будет предложена система курсов Data Culture в определенной вилке «сквозного уровня продвинутости». Более того, эти системы курсов определятся спецификой предметных областей.
Внедрение дисциплин Data Culture будет происходить поэтапно. В 2017/2018 учебном году будут включены в учебные планы обязательные и элективные курсы по направлению Data Science для части образовательных программ, но таковых будет более половины. Например, у студентов-гуманитариев, юристов и дизайнеров появится вводный курс по цифровой грамотности, программы экономистов дополнятся дисциплиной по машинному обучению, политологов – анализу социальных сетей, у статистиков появится курс по программированию и извлечению и анализу интернет-данных. С 2018 года к проекту примкнут все образовательные программы.
Для реализации проекта Data Culture предполагается привлечение преподавательского состава как из академической среды (преподаватели факультета компьютерных наук, сотрудники департамента математики факультета экономических наук и общеуниверситетской кафедры высшей математики и т.д.), так и из индустрии (участники сообществ по анализу данных, участники тематических мероприятий по анализу данных, проводимых в IT-компаниях). Более того, преподаватели факультетов, которые уже погружены в работу с данными в рамках своей профессиональной деятельности, также будут разрабатывать курсы в рамках проекта Data Culture для студентов своих и смежных факультетов.